
Custom Software Development Services
Transform and grow your business. Join over 230 technology leaders who have created applications using our company specializing in custom software development projects.
Engage product design and development experts and reach your business goals
C-executives and business owners from small and medium enterprises collaborate with our dedicated product teams to outperform their competitors and generate business value. Our friendly and trustful relationships with clients enable us to offer our advice and build unique custom solutions.



Client Value & Trust
Learn how entrepreneurs, business and technology leaders who are after software driven innovation are collaborating with our high-performing teams.


Selleo has proven to be one of the best outsource development partners we've ever used. They are reliable, communicative, always helpful, consistently deliver to a high standard and are an absolute pleasure to work with too.


Leverage our domain expertise and technical knowledge to build a one-of-a-kind custom solution
Schedule a consultationHow we start collaboration
We serve business and tech leaders building custom software
With custom application development expertise in UX Design, Front-end and Back-end implementations our developers and designers can help you execute quickly and ship products faster. We specialize in designing, building, and maintaining distributed multi-tenant, secure, and robust custom software solutions.
Cost-effective development
We all speak English and advocate one team one room rule. Our accessibility and strategic feedback ensure broadband communications, productivity and efficient delivery.
Cross-functional agile team
We work in Scrum and have a sense of ownership. Designers and developers care about clients showing initiative and a proactive approach to problem-solving.
Technology expertise
Leverage the up-to-dateness of our technical skills, high-quality coding practices and expertise in making architectural decisions related to app development.
Our experience, your success
We take pride in our commitment to quality and excellence and our high Clutch rating is a reflection of that. We always strive to exceed expectations and deliver exceptional results to every client we serve.






Hire experienced software development team today!
Product Owners and CTOs in start-ups and SMEs craft their SaaS products or build their own cloud-based solutions with our teams.
Contact us
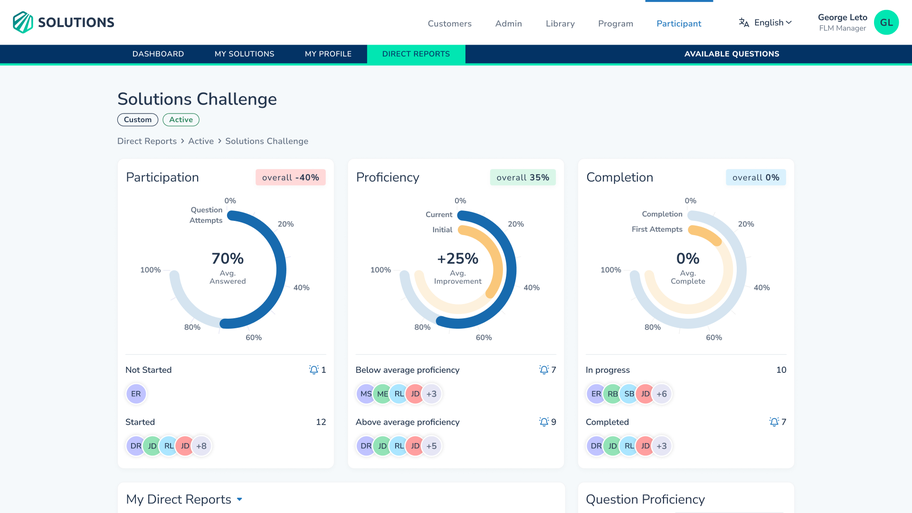
How we helped clients grow their businesses
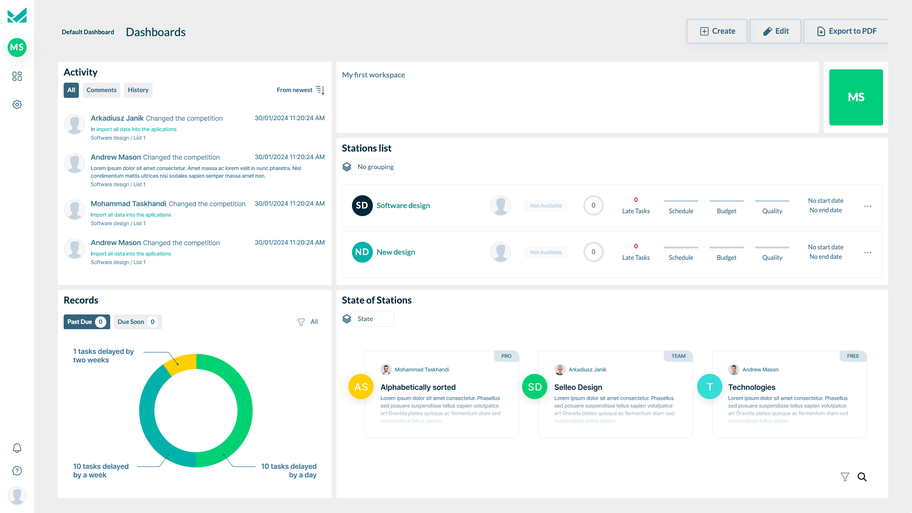
From an MVP to a successful e-learning platform
Defined Learning contacted us to develop the MVP version of the Defined Careers app in Ruby on Rails. The whole code-base was built from scratch which later was integrated with Defined other existing systems. Our UX/UI team was also responsible for the designs later.View project

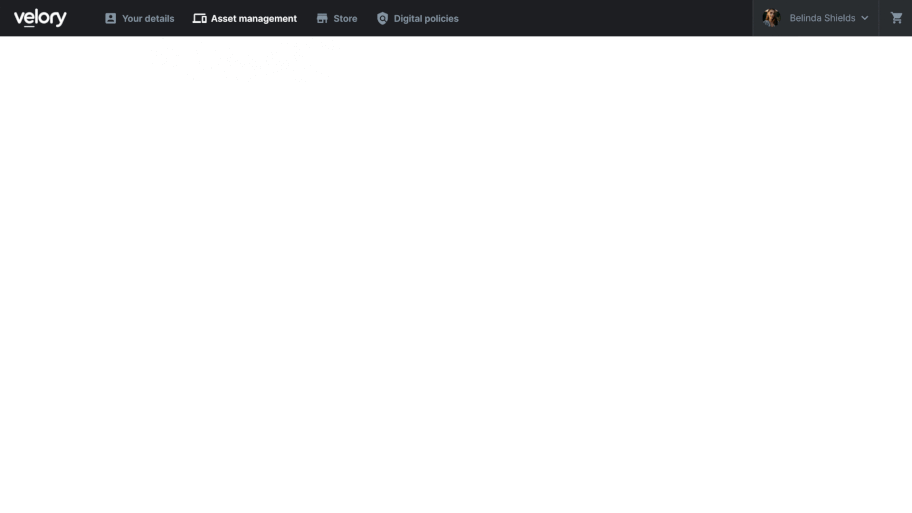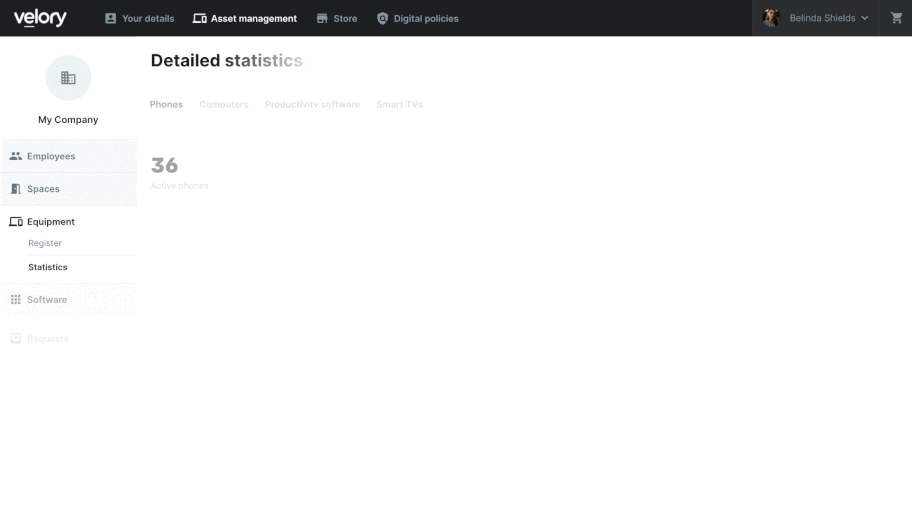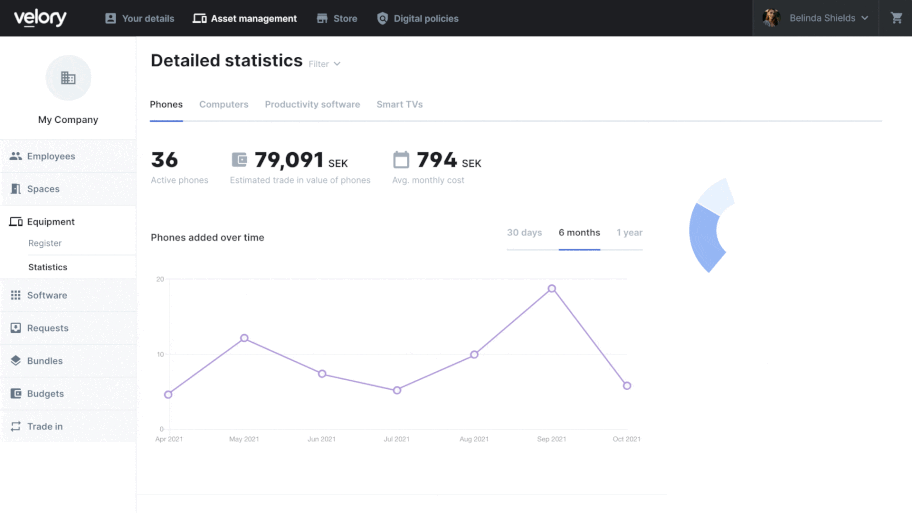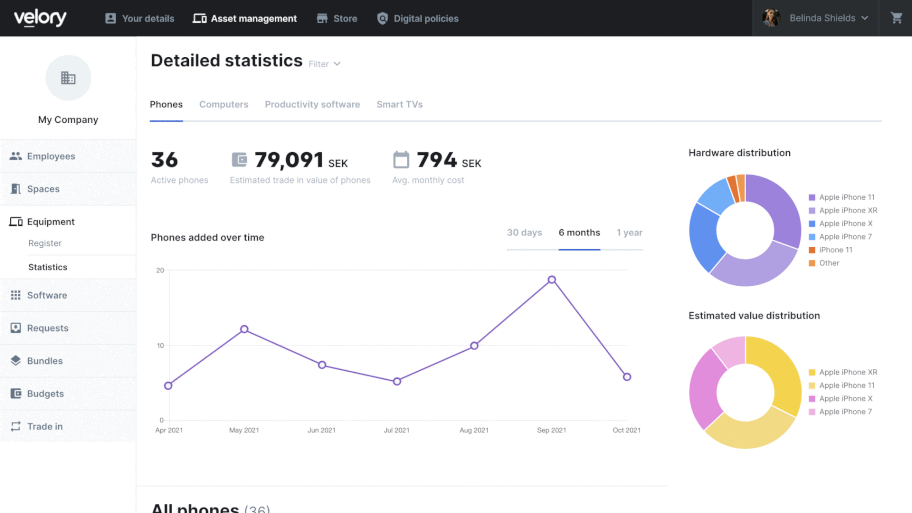
- Outdated manual processes: If manual processes are slowing down your organization, custom software can modernize and streamline them.
- Integration challenges: If current systems can't effectively communicate or share data, custom software can be developed to integrate them.
- Unique business requirements: If your organization has specific needs that can't be met by existing software, custom software can be designed to meet those needs.
- Scalability limitations: If your organization is expanding and existing systems can't keep up, custom software can be designed to grow with your business.
- Security risks: If sensitive data is being handled, custom software can be developed with stronger security measures to protect that data.
- Competitive advantage: Custom software development company can give your organization a unique advantage by providing a customized solution that meets your specific needs.
As a software development firm, we can deliver our services in two different ways:
- Dedicated team: a method in software development services where a company is contracted to deliver a specific, well-defined product or set of products within a specified timeframe and budget. The focus is on providing the project goals, rather than ongoing support or maintenance.
- Staff augmentation: in software development, works by adding external software developers to a company's existing in-house development team. The external developers are integrated into the team and work alongside the in-house developers to complete the software project.
Selleo advocates following the rules and principles of Agile and Lean software development methodologies as the best approach to managing projects. We use Scrum as a lightweight agile process framework to manage our software development as it ensures an appropriate level of communication and collaboration with the client people. We perceive it to be a critical success factor in the execution of outsourced projects. The methodology many times proved to greatly help to integrate all the team members involved in the case of both independent and augmented development teams.

Our custom software development process involves several key stages:
Requirements analysis: We engage in conversations with you to precisely understand your needs and business goals.
Designing: We create a software design and prototype that takes into account your requirements.
Programming: Our team of programmers begins the process of software development.
Testing: We thoroughly test the software to ensure it functions correctly and meets all requirements.
Deployment and support: We assist in the software deployment process and provide technical support after deployment.
Our Articles about Custom Software Development

software development
How to Create a Career Path for Software Development Teams?
Having a structured career path for your developers may be essential when boosting their engagement or getting top-tier talent. See how we do it with Developer Path! Ready-made progression path that is specialized for IT businesses.
Mar 29, 2024

saas
What Are the Challenges of Integrating AI into Existing SaaS Platforms?
Do you know that AI and SaaS are a powerful pair? However, there are challenges that may occur during the implementation phase. Read out our expert thoughts and find out how to deal with them.
Mar 22, 2024

software development
IT Outsourcing Contracts | A Simple Guide To Complex Legal Matters
Outsourcing comes with great advantages for your company, but can also have a lot of threats and complications when it comes to dealing with and maintaining legal contracts. This post will help you overcome them.
Oct 11, 2021



